Basics of Machine Learning Series
Introduction
Neural networks were developed to mimic the way neurons in a brain work. Typically, a neuron has input connections and output connections. So basically, neuron is a computational unit which takes a set of inputs and produces output. So the basic functionality of neurons is tried to be replicated in these computational units. For example, neurons in brain interact with each other using electrical signals and are selectively activated based on certain parameters. This behaviour is transferred to a unit in neural networks using activation function which would be explained later in the post.
Neuron Model: Logistic Unit
Below is the representation of a basic logistic unit neuron model,

Here, \(x_0, \cdots, x_3\) are the input units connected to the neuron and can be considered similar to dendrites getting signals from other neurons. \(h_\theta(x)\) is the activation function which basically decides whether or not should the neuron get activated or excited. The term \(x_0 = 1\), also called bias unit, plays an important role in the decision made for excitation of neuron. In case of a logistic unit the activation function is a logistic function or sigmoid function i.e. the neuron has a sigmoid (logistic) activation function. Sigmoid function is given by,
Parameters of the model, \(\theta_0, \cdots, \theta_n\) are also sometimes called weights of the model and represented by \(w_1, \cdots, w_n\).
Neural Network
A group of these neuron units together forms a neural network. Below is a representation of neural network,
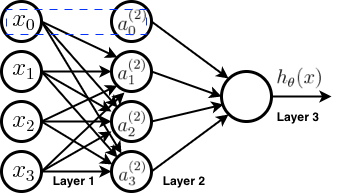
- Where
- network has 3 layers
- layer 1 is called input layer
- layer 3 is called output layer
- remaining layers are called hidden layers. In this case there is only one hidden layer, but it is possible to have multiple hidden layers
- \(x_0\) and \(a_0^{(2)}\) are the bias terms and equal 1 always. They are generally not counted when the number of units in a layer are calculated. So, layer 1 and layer 2 have 3 units each.
- Notations
- \(a_i^{(j)}\) is the activation of unit i in layer j
- \(\Theta^{(j)}\) is the matrix of weights controlling function mapping from layer j to layer j+1.
So, the network diagram above depicts the following computations,
From the equation above one can generalize, if a network has \(s_j\) units in layer j and \(s_{j+1}\) units in layer j+1, then \(\Theta^{(j)}\) is a matrix of dimension \((s_{j+1} * (s_j + 1))\).
Vectorization of Network Computation
Consider (2) can be written as,
- Where \(z_i^{(j)} = \Theta_{i0}^{(j-1)}\,x_0 + \Theta_{i1}^{(j-1)}\,x_1 + \Theta_{i2}^{(j-1)}\,x_2 + \Theta_{i3}^{(j-1)}\,x_3\)
Given \(x=\begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_n\end{bmatrix}\) and \(z^{(j)}=\begin{bmatrix} z_1^{(j)} \\ \vdots \\ z_n^{(j)} \end{bmatrix}\), then computation for \(z^{(j)}\) can be vectorized as follows,
- Where
- \(a^{(1)} = x\)
- \(\Theta^{(j-1)}\) is a matrix of dimensions \((s_j * (s_{j-1}+1))\)
- \(s_j\) is number of activation nodes
After (5), bias unit, \(a_0^{(j)} = 1\) is added to the activation vector of layer j and then the process repeats to get activation for the next layer, i.e. (3) is written as,
- Where \(\Theta^{(j)}\) is a matrix of dimensions \((s_{j+1} * (s_j + 1)) \)
Process of calculation of activations cascading across layers is called Forward Propagation.
Nueral Network and Logistic Regression
If one looks closely at the neural network diagram above, it can be easily seen that if one removes the layer 1, the schema looks same as a logistic regression. It is infact a logistic regression model if the hidden layer is the direct features (input layer) fed to the neuron because the activation function of the neuron is logistic (sigmoid) function. So, effectively the neural network shown above is a logistic regression where the features for classification are learnt by the hidden layer and not fed manually by human intervention. Each feature in hidden layer is mapped from the input layer. Because of this architecture there is a chance of learning much better features than started with or one can make using the higher order polynomial terms and hence there is a probability of reaching better hypotheses with neural networks.
Architecture of Neural Network
It is possible to have different kinds of architecture for the neural network. By architecture, it means to have different schema, i.e. number of neurons per layer can vary, number of layers used can vary, the way the neurons are connected to each other can vary and similarly various other variations are possible in terms of optimization parameters, activation etc. When then number of hidden layers is more than one, they are known as deep neural networks.
REFERENCES:
Machine Learning: Coursera - Model Representation I
Machine Learning: Coursera - Model Representation II