Basics of Machine Learning Series
Introduction
Neural networks can be used to build all types of function. This post tries to map functions of logical operations using the network. How the parameters are derived in explained in the later posts.
AND Gate
Using a single neuron, it is possible to achieve the approximation of an and gate. The architecture with the parameters can be seen below.
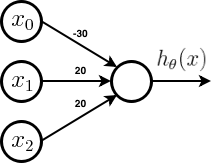
The hypothesis for the above network is given by,
- Where g is the sigmoid function which asymptotes at 0 and 1.
The output table for the hypothesis above is given below.
| \(x_1\) | \(x_2\) | \(h_\theta(x)\) |
|---|---|---|
| 0 | 0 | \(g(-30) \approx 0\) |
| 0 | 1 | \(g(-10) \approx 0\) |
| 1 | 0 | \(g(-10) \approx 0\) |
| 1 | 1 | \(g(10) \approx 1\) |
The values of \(h_\theta(x)\) is nothing but the expected value of the AND gate.
OR Gate
Similarly, using a single neuron, it is possible to achieve the approximation of an or gate. The architecture with the parameters can be seen below. It is same as AND gate but the bias weight is changed.
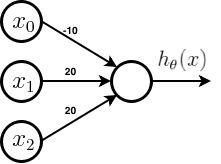
The hypothesis for the above network is given by,
- Where g is the sigmoid function which asymptotes at 0 and 1.
The output table for the hypothesis above is given below.
| \(x_1\) | \(x_2\) | \(h_\theta(x)\) |
|---|---|---|
| 0 | 0 | \(g(-10) \approx 0\) |
| 0 | 1 | \(g(10) \approx 1\) |
| 1 | 0 | \(g(10) \approx 1\) |
| 1 | 1 | \(g(30) \approx 1\) |
The values of \(h_\theta(x)\) is nothing but the expected value of the OR gate.
NOT Gate
Unlike the previous two examples, NOT gate is a unary operator, but still simple weights can give easy implementation of the NOT gate. The architecture and the parameters are shown below.
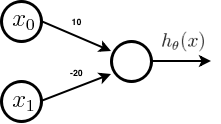
The hypothesis for the above network is given by,
- Where g is the sigmoid function which asymptotes at 0 and 1.
The output table for the hypothesis above is given below.
| \(x_1\) | \(h_\theta(x)\) |
|---|---|
| 0 | \(g(10) \approx 1\) |
| 1 | \(g(-10) \approx 0\) |
The values of \(h_\theta(x)\) is nothing but the expected value of the NOT gate.
(NOT \(x_1\)) AND (NOT \(x_2\))
Unlike the previous examples, this operation does not look straight forward, but actually it is. Here is an architecture implementation of the above gate.
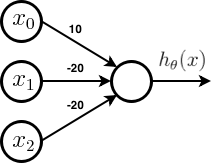
The hypothesis for the above network is given by,
- Where g is the sigmoid function which asymptotes at 0 and 1.
The output table for the hypothesis above is given below.
| \(x_1\) | \(x_2\) | \(h_\theta(x)\) |
|---|---|---|
| 0 | 0 | \(g(10) \approx 1\) |
| 0 | 1 | \(g(-10) \approx 0\) |
| 1 | 0 | \(g(-10) \approx 0\) |
| 1 | 1 | \(g(-30) \approx 0\) |
The values of \(h_\theta(x)\) is nothing but the expected value of the (NOT \(x_1\)) AND (NOT \(x_2\)) operation.
Perceptron Limitation
All the examples untill this one were linearly seperable and hence were solved using a single neuron. But and XOR Gate is not linearly seperable as was the case with AND and OR gates and this can be clearly seen in the plot below.
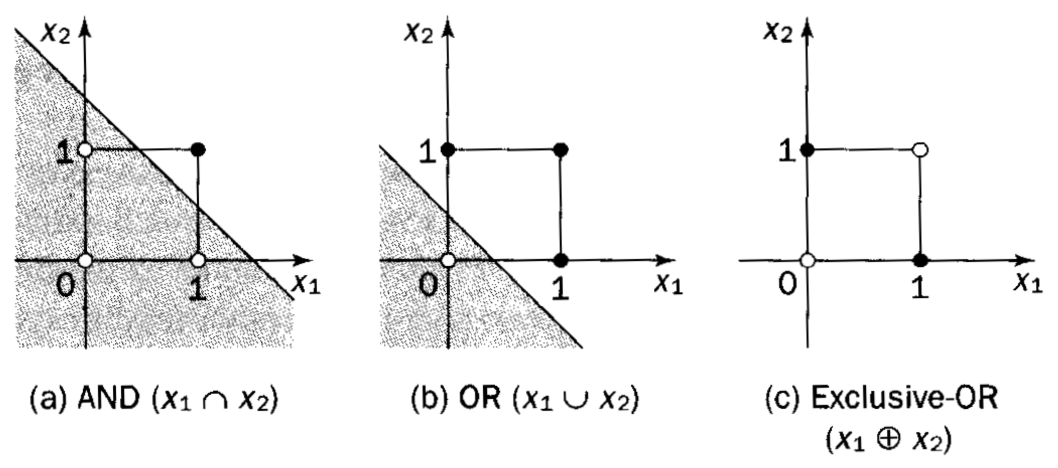
It is evident that there is no single straight line that can seperate the two classes in plot (c) and hence termed as not linearly seperable. This is a major drawback of perceptron (single layer neural networks).
There is a simple proof for concluding that the XOR is not linearly seperable. Say, perceptron were capable of separating the two classes, then it would mean that there exists a set of weights (or parameters), \(\theta_0,\, \theta_1,\,\theta_2\) such that the hypothesis is given by,
Then the above hypothesis should satisfy the following truth table,
| \(x_1\) | \(x_2\) | \(x_1\,XOR\,x_2\) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Substituting and equating to 0, the hypothesis, following inequalities are generated that would determine the decision boundary.
Substituting \(b = -\theta_0\), above inequalities can be written as,
It can be seen that the first three inequalities directly contradict the fourth one. Which means that the very first assumption made that there exist such parameters \(\theta_0,\, \theta_1,\,\theta_2\) was incorrect. Hence, the XOR gate is not linearly seperable.
This is where the utility and finesse of multi-layer neural network in deriving intricate features from the input features can be seen in action.
XNOR Gate
For simplicity, let’s consider a XNOR gate which is nothing but the negation of an XOR gate. So, it would not be wrong to say that if XNOR gate is achieved, XOR gate is not very far. Consider the following neural network with one hidden layer and the given weights.
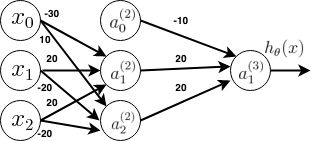
Here if weights are seen carefully, \(a_1^{(2)}\) is nothing but the AND gate and \(a_2^{(2)}\) is nothing but (NOT \(x_1\)) AND (NOT \(x_2\)). Similarly the output neuron is nothing but the OR gate. It calculates the following result table,
| \(x_1\) | \(x_2\) | \(a_1^{(2)}\) | \(a_2^{(2)}\) | \(h_\theta(x)\) |
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 1 |
The values of \(h_\theta(x)\) is nothing but the expected value of the XNOR operation.
This gives the intuition that the hidden layers are calculating a more complex input which inturn helps to turn the problem into a linearly seperable one using the transformations. This is the main reason the neural networks are fairly powerful classifiers because as the depth (or number of hidden layers) of the neural network increases it can derive more and more complex features for the final layer.
REFERENCES:
Machine Learning: Coursera - Examples and Intutions I
Machine Learning: Coursera - Examples and Intutions II