Basics of Machine Learning Series
Derivative of Sigmoid
The sigmoid function, represented by \(\sigma\) is defined as,
So, the derivative of \eqref{1}, denoted by \(\sigma’\) can be derived using the quotient rule of differentiation, i.e., if \(f\) and \(g\) are functions, then,
Since \(f\) is a constant (i.e. 1) in this case, \eqref{2} reduces to,
Also, by the chain rule of differentiation, if \(h(x) = f(g(x))\), then,
Applying \eqref{3} and \eqref{4} to \eqref{1}, \(\sigma’(x)\) is given by,
Mathematics of Backpropagation
(* all the derivations are based scalar calculus and not the matrix calculus for simplicity of calculations)
In most of the cases of algorithms like logistic regression, linear regression, there is no hidden layer, which basically zeroes down to the fact that there is no concept of error propagation in backward direction because there is a direct dependence of model cost function on the single layer of model parameters.
Backpropagation tries to do the similar exercise using the partial derivatives of model output with respect to the individual parameters. It so happens that there is a trend that can be observed when such derivatives are calculated and backpropagation tries to exploit the patterns and hence minimizes the overall computation by reusing the terms already calculated.
Consider a simple neural network with a single path (following the notation from Neural Networks: Cost Function and Backpropagation) as shown below,
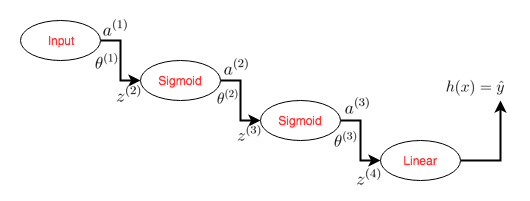
where,
where \(g\) is a linear function defined as \(g(x) = x\), and hence \(g’(x) = 1\). \(\sigma\) represents the sigmoid function.
For the simplicity of derivation, let the cost function, \(J\) be defined as,
where,
Now, in order to find the changes that should be made in the parameters (i.e. weights), partial derivatives of the cost function is calculated w.r.t. individual \(\theta’s\),
One can see a pattern emerging among the partial derivatives of the cost function with respect to the individual parameters matrices. The expressions in \eqref{9}, \eqref{10} and \eqref{11} show that each term consists of the derivative of the network error, the weighted derivative of the node output with respect to the node input leading upto that node.
So, for this network the updates for the matrices are given by,
Forward propagation is a recursive algorithm takes an input, weighs it along the edges and then applies the activation function in a node and repeats this process until the output node. Similarly, backpropagation is a recursive algorithm performing the inverse of the forward propagation, i.e. it takes the error signal from the output layer, weighs it along the edges and performs derivative of activation in an encountered node until it reaches the input. This brings in the concept of backward error propagation.
Error Signal
Following the concept of backward error propagation, error signal is defined as the accumulated error at each layer. The recursive error signal at a layer l is defined as,
Intuitively, it can be understood as the measure of how the network error changes with respect to the change in input to unit \(l\).
So, \(\delta^{(4)}\) in \eqref{8}, can be derived using \eqref{13},
Similary the error signal at previous layers can be derived and it can be seen how the error signal of the forward layers get transmitted to the backward layers
Using \eqref{14}, \eqref{15} and \eqref{16}, \eqref{12} can be written as,
which is nothing but the updates to individual parameter matrices based on partial derivatives of cost w.r.t. individual matrices.
Activation Function
Generally, the choice of activation function at the output layer is dependent on the type of cost function. This is mainly to simplify the process of differentiation. For example, as shown in the example above, if the cost function is mean-squared error then choice of linear function as activation for the output layer often helps simplify calculations. Similarly, the cross-entropy loss works well with sigmoid or softmax activation functions. But this is not a hard and fast rule. One is free to use any activation function with any cost function, although the equations for partial derivatives might not look as nice.
Similarly, the choice of activation function in hidden layers are plenty. Although sigmoid functions are widely used, they suffer from vanishing gradient as the depth increases, hence other activations like ReLUs are recommended for deeper neural networks.
REFERENCES:
Artificial Neural Networks: Mathematics of Backpropagation (Part 4)
Which activation function for output layer?