Introduction
Smart reply is an end to end method for automatically generating short yet semantically diverse email repsonses. The feature also depends on some novel methods for semantic clustering of user-generated content that requires minimal amount of explicitly labeled data.
Google reveals that around 25% of the email responses are 20 tokens or less in length. The high frequency of short replies was the major motivation behind developing an automated reply assist feature. The system exploits concepts of machine learning such as fully-connected neural networks, LSTMs etch.
Major challenges that have been addressed in building this features includes the following:
- High repsonse quality in terms of language and content.
- Utility maintained by presenting a variety of responses.
- Scalable architecture to serve millions of emails google handles without significant latencies.
- Maintaining privacy by ensuring that no personal data is leaked while generating training data. Only aggregate statistics are inspected.
Smart Reply
Smart reply consists of the following components:
- Response Selection: An LSTM network processes the incoming messages and produces the most likely responses. To improve scalability and increase speed of processing, only approximate best responses are found.
- Response Set Generation: In order to maintain high quality, the responses are selected from a response state generated offline using semi-supervised graph learning approach.
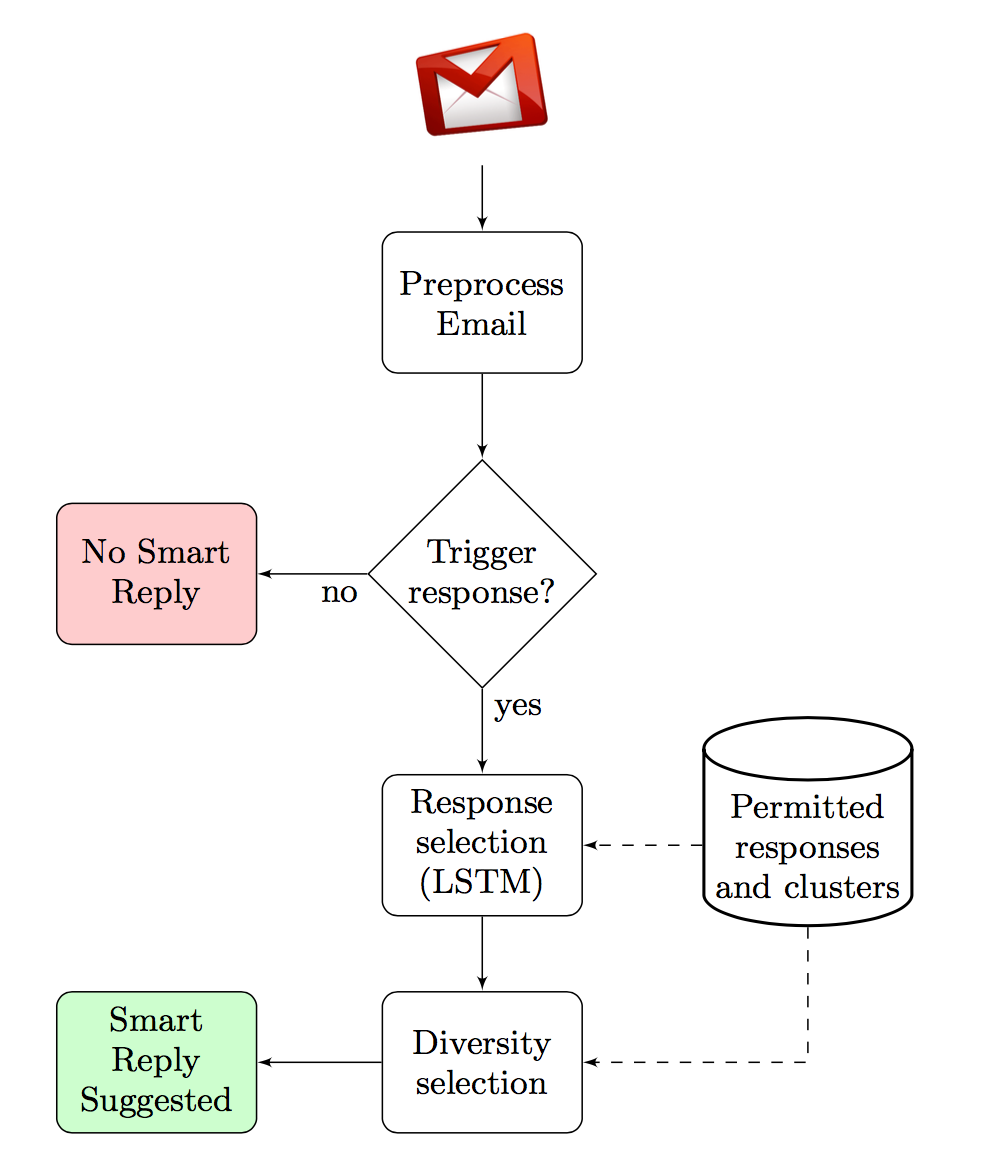
- Diversity: After generating the most likely responses, a smaller set of responses are chosen among them to maximize the utility which requires enforcing diverse semantic intents among the presented options.
- Triggering Model: A feedforward neural network decides whether or not to suggest responses, which further improves the utility by not showing suggestions when they are unlikely to be used.
Background
The entire application of smart reply can be basically broken down into two core tasks:
- predicting responses
- identifying a target response space
While the task of finding the apt response has be attempted before, it has never been applied to a production environment at such a scale. It is this widespread use of the application that requires it to deliver high quality responses at all the instances. This is achieved by choosing the responses from a set of pre-identified response space.
Which leads to the second core task of identifying the target response space. This is achieved by using an algorithm called Expander Graph Learning Approach. It is used because it scales well to really large datasets and large output sizes. Generally used for knowledge expansion and classification tasks, smart reply is the first attempt to use it for semantic intent clustering.
Selecting Responses
The fundamental aim of smart reply is to find the most likely response given an original message text. i.e. given an original message \(o\) and the set of all possible responses \(R\), find,
In order to acheive this a model is built to score the responses and then response with the highest score is picked.
LSTM Model
- Since a sequence of tokens \(r\) is being scored conditional on another sequence of characters \(o\), the task is a natural fit for sequence to sequence learning.
- Input to the model is the original message \(\{o_1, o_2, \cdots o_n\}\)
- The output is the conditional probability distribution of sequence of response tokens given the input:
The distribution in \eqref{2} can be further factorized as,
In practice, the sequence of original message is fed to the LSTM, which then encodes the entire message in a vector representation. Then given this state, a softmax output is computed, which is interpretted as \(P(r_1|o_1, \cdots, o_n)\)(probability distribution of the first response token).
Similarly, as the response tokens are fed in, softmax at each timestep \(t\) is interpretted as \(P(r_t|o_1, \cdots, o_n, r_1, \cdots, r_{t-1})\)
Using the factorization in \eqref{3}, these softmax scores can be used to compute \(P(r_1, r_2, \cdots, r_m | o_1, o_2, \cdots, o_n)\).
Training involves the following points:
- maximize the log probability of observed responses, given their respective original messages, i.e.
- train using stochastic gradient descent using AdaGrad.
- training is done on a distributed system because of the size of the dataset.
- recurrenct projection layer helped improve quality and time of convergence.
- gradient clipping helps stabalize training.
Inference: At the time of inference one can feed in the original message and then use the output of the softmaxes to get a probability distribution over the vocabulary at each timestep. These can be used in a variety of ways:
- to draw a random sample from the response distribution. This is done by sampling one token at each timestep to feed it back into the model.
- to approximate the most likely response given the original message. This can be done greedily by taking most likely token at each timestep and feeding it back in. A less greedy strategy is to use beam search, i.e. take the top \(b\) tokens and feed them in, then retain the best \(b\) response prefixes and repeat.
- to determine the likelyhood of a specific response candidate. Done by feeding each token of the candidate and using softmax output to get the likelyhood of next candidate token.
Challenges
Response Quality
- In order to surface responses to the users, responses must be always high quality in terms of style, tone, diction, and content. Since the models are trained on real-world data, one has to account for the possibility where the most response is not necessarily a high quality response. Even the most frequent responses might not be appropriate to suggest to users because it could contain poor grammar, spelling or machanics (like you’re the best!) or it could also convey a sense of familiarity that is likely to be offensive (like thanks hon!) etc.
- While restricting the vocabulary can take care of issues such as profanity or spell errors, it would not be sufficient in averting a politically incorrect statement that can be formed in a wide variety of ways.
- Hence, smart reply uses a semi-supervised learning to build the target repsonse space \(R\) comprising of only high quality responses.
- Hence the model described is used to choose the best response among \(R\), instead of best response from any sequence of words in the vocabulary.
Utility
- Suggestions are most useful when they are highly specific to the original message and express a diverse intent.
- Generally the outputs from LSTM observed tend to (1) favor common but unspecific responses and (2) have little diversity.
- Specificity of the responses is increased by penalizing the responses that are applicable to a broad range of incoming messages.
- In order to increase the breadth of options presented to users, diversity is enforced by exploiting the semantic structure of \(R\).
- Utility of responses is also boosted by passing the incoming message first through a triggering model which decides whether or not it is appropriate for suggestions to pop up.
Scalability
- Scoring every candidate \(r \in R\) would require \(O(|R | l)\) LSTM steps where \(l\) is the length of the longest response.
- This would mean a growing response time as the number of responses in \(R\) increases over time.
- In general, an efficient algorithm for this purpose should not be a function of \(|R|\)
- In order to achieve this, the responses among \(R\) are organized as a trie, followed by a left-to-right beam-search but retain only the hypotheses that appear in the trie.
- This search process has a complexity of \(O(bl)\) where both \(b\) and \(l\) are in a range of 10-30, which greatly reduces the time it would take to generate the responses.
- Although the search only approximates the best responses in \(R\), its results are very similar to what one would get by scoring and ranking all \(r \in R\), even for a small \(b\).
- Also first pass through the triggering model, reduces the average time a message has to spend in LSTM computations.
Response Set Generation
- The goal of this step is to generate a structured response set that effectively captures various intents conveyed by people in natural language conversations.
- The target response space is required to capture both variablity in language and intents.
- The results are used in two ways - (1) define a response space and (2) promote diversity among chosen suggestions.
- Response set is constructed by aggregating the most frequently used sentences among the preprocessed data.
Canonicalizing Email Responses
- Involves generating a set of canonicalized responses that capture the variability in language.
- This is done by performing a dependency parse on all the sentences and then using the syntactic structure to generate a canonicalized representation.
- Words, phrases that are modifiers or not attached to the head words are ignored.
Semantic Intent Clustering
- partition the responses into semantic clusters where each cluster represents a meaningful response intent.
- all the messages within a cluster share the same semantic meaning but may appear different in structure.
- this helps digest the entire information present in frequent responses into a coherent set of semantic cluster
- because of the lack of data available to train a classifier, a supervised model cannot be trained to predict the semantic cluster of a candidate response.
- another hindrance in performing supervised learning is that the semantic space classes cannot be all defined a priori.
- hence the semi-supervised technique is used for achieving this.
Graph Construction
- Start by manually defining the clusters sampled from top frequent responses.
- A small number of responses are added as seed for the clustering.
- This leads to a base graph, where frequent responses are represented by nodes, \(V_R\). Lexical features (n-grams and skip grams upto a length of 3) are extracted for the responses and populated in graph as the feature nodes, \(V_F\). Edges are created between the pair of nodes, \((u,v)\) where \(u \in V_R\) and \(v \in V_F\). Similarly, nodes are created for manually labelled examples, \(V_L\).
Unsupervised Learning
- The constructed graph captures the relationship between the canonicalized responses via feature nodes.
- Semantic intent for each repsonse node is learnt by propagating intent information from manually labelled examples through the graph.
The algorithm works to minimize the following objective function for the response nodes:
where
- \(s_i\) is an indicator function equal to 1 if node \(i\) is a seed else 0.
- \(\hat{C_i}\) is the learnt semantic cluster distribution for response node \(i\).
- \(C_i\) is the true label distribution (i.e. for the manually provided examples)
- \(\mathcal{N}_{\mathcal{F}} (i)\) and \(\mathcal{N}_{\mathcal{R}} (i)\) represent the feature and response neighbourhood of node \(i\).
- \(\mu_{np}\) is the predefined penalty for neighbouring nodes with divergent label distributions.
- \(\hat{C_j}\) is the learnt label distribution for feature neighbour \(j\).
- \(w_{ij}\) is the weight of feature \(j\) in response \(i\).
- \(\mu_{pp}\) is the penalty for label distribution deviating from prior, Uniform Distribution \(U\).
Similarly, the objective is to reduce the following objective function for the feature nodes:
\eqref{5} and \eqref{6} are alike except that \eqref{6} does not have the first term as there are no seed labels for the feature nodes.
The objective functions \eqref{5} and \eqref{6} are jointly optimized for all the nodes. In order to discover the new clusters the algorithm is run in phases, in which randomly 100 new responses are sampled among the unlabeled nodes. These are treated as the potential new clusters and labeled with there canonicalized representations after which the algorithm is rerun and the process is repeated for the unlabeled nodes.
Cluster Validation
- Finally, the top \(k\) members from each semantic cluster are extracted and sorted by their label scores.
- The set of (response, cluster label) pairs are then validated by human raters.
Suggestion Diversity
- The LSTM model is trained to returned the approximate best response among the target response set.
- The responses are penalized if they are too general to be valuable to any user.
- The next challenge lies in choosing a small number of responses to display to the user which maximizes the utility.
- A straight-forward way of doing this can be to choose the top \(N\) responses and present them to the user. But in practice it is observed that such responses tend to be very similar. It is obvious to anyone that the likelihood of one of the repsonses being useful is greatest when none of the responses presented to the users are redundant, i.e. it would be wasteful to present a user with three responses that are a variation of same sentence.
- The second and more optimal approach to suggest responses to users would include enforcing diversity. This is achieved by:
- omitting redundant responses.
- enforcing negative or positive responses.
Omitting Redundant Responses
- The strategy states that a user should never see two responses with the same intent.
Intent can be thought of as a cluster of responses that have a common communication purpose.
- In smart reply, every suggested responses is associated with a exactly one intent. These intents are learnt using the semi-supervised learning algorithm explained above.
- The actual diversity strategy simple: the top responses are iterated over in order of decreasing score. Each response is added to suggestion list unless its intent is already covered by a response in the suggestion list.
Enforcing Negatives and Positives
- It is observed that the LSTM trained has a strong tendency towards positive responses, whereas negative responses generally get a low score.
- It might be reflective of the style of email conversations: positive replies are more common and when the replies are negative people prefer more indirect wording.
- Since, it is important to give out and option of repsonding negatively, the following strategy is followed:
If the top two responses (chosen from different intents) contain atleast one positive and none of the three responses are negative, the third response is replaced with a negative one.
-
A positive response is the one that is clearly affirmative. In order to find the negative response to be included as the third option, a second LSTM pass is performed, in which the search is restricted to only to the negative responses in the target set.
-
It might also be the case that an incoming message triggers exclusively negative responses. In which case, an analogous strategy for enforcing positives is employed.
Triggering
- This is a second model (in this case a fully-connected feed-forward neural network which produced probability score) that is responsible for filtering messages that are bad candidates for suggesting responses. These might include emails that require longer responses, or emails that do not require a response at all.
- On an average this system only decides that 11% of the incoming messages should get processed for smart reply. This selectivity further helps to speed up the process of analyzing the incoming emails, and decrease the time spent on LSTM and hence inturn reduce the infrastructure costs.
- The two main objectives that this system should fulful are:
- it should be accurate enough to decide when a smart reply should not be generated
- it should be fast.
- The choice of model is because it has been repeatedly observed that these ANN outperform linear models such as SVMs or linear regression on NLP tasks.
Data and Features
- Data includes the set of emails in the pair \((o, y)\), where \(o\) is an incoming message and \(y\) is a boolean true or false based on whether or not a email was replied to. For the positive class, only the messages that were replied to from a mobile device are considered.
- Since the number of emails that are not replied to are found to be higher, the negative class examples are downsampled to match the number of positive class examples.
- Features (unigrams and bigrams) are extracted from message body, subject and headers. Other social signals such as whether or not the sender is in receipent’s address book etc is also used.
Network Architecture and Training
- Feed forward neural network with embedding layer and three fully connected hidden layers
- Feature hashing is used to bucket rare words that are not present in the vocabulary.
- Embeddings are aggregated by summation within a features (like bigram etc.)
- Activation function: ReLu and Dropout layers are used.
- Trained using AdaGrad optimization technique.
Evaluation and Results
Data
- For the LSTM model data consists of incoming messages and its responses by a user.
-
For the triggering model, messages are used with the label describing whether or not they were replied to from a mobile device.
- The following preprocessing techniques are used:
- Language detection: non-english messages are discarded.
- Tokenization: messages and subjects are broken down into words and punctuations
- Sentence segmentation: sentence boundaries are detected in the message body
- Normalization: infrequent words and entities like personal informations are replaced by special tokens.
- Quotation removal: Quoted original messages and forwarded messages are removed.
- Salutation/close removal: salutations and closing notes are removed.
- After preprocessing the size of the training data is 238 million messages, which includes 153 million messages that have no response.
Conclusions
- Standard binary performance metrics are observed for triggering model: Precision, recall and area under the ROC curve.
- AUC of triggering model is 0.854
- For the LSTM model Precision, Mean Reciprocal Rank and Precision@K is observed.
- A model with lower perplexity assigns a higher likelyhood to the test responses, and hence should be better at predicting responses. Perplexity of smart reply is 17.0 (by comparison, and n-gram model with katz backoff and maximum order of 5 has a perplexity of 31.4)
A perplexity equal to \(k\) means that when the model predicts the next word, there are on average \(k\) likely candidates.
- In an ideal scenario the perplexity of the system would be 1, i.e. one knows exactly what should be the next word. The perplexity on a set of \(N\) test samples is computed using the following formula:
where
- \(W\) is the total number of words in the \(N\) samples.
- \(\hat{P}\) is the learnt distribution
-
\(r^i\) and \(o^i\) are the \(i-th\) repsonse and original message.
- The model is also evaluated on the response ranking. Simply put, the rank of the actual response with respect to other responses in R is evaluated. Using this, the mean reciprocal rank (MRR) is calculated using:
-
Additionally, Precision@K (for a given value of K, the number of cases for which target response \(r\) is within the topK responses that were ranked by the model) is also computed.
-
On a daily basis, the smart reply system generates 12.9k unique suggestions that belong to 376 unique semantic clusters, out of which the users utilized, 31.9% of the suggestions and 83.2% of the unique clusters.
- Among the selected responses, 45% are the 1st responses, 35% 2nd responses, and 20% 3rd responses.
- If using only the straight-forward approach instead of enforcing diversity, the click through rates drop by roughly 7.5%.
REFERENCES:
Smart Reply: Automated Response Suggestion for Email
Save time with Smart Reply in Gmail