Introduction
- It was originally an HP research project between 1984 and 1994, which was presented at 1995 UNLV Annual Test of OCR Accuracy where it performed beyond expectations.
- Purpose of tesseract was integration with the flatbed HP scanners with objectives such as compression which was not possible with the then existing commercial OCR solutions which were struggling with accuracy.
- During a phase of development, work concentrated on improving rejection efficiency than on base-level accuracy.
- Finally in 2005, Tesseract was released as an open-source project by HP available at Google Code until it was finally moved to Github for open-source contribution.
Architecture
-
Because of HP’s proprietary layout analysis technology, Tesseract did not have it’s own dedicated layout analyser. As a result, Tesseract assumes the inputs to be binary image with optional polygonal text regions defined.
-
Connected Component Analysis is the first step in which the outlines of the components are stored. Outlines are gathered together, purely by nesting, into Blobs.
-
Blobs are organized into text lines, and the the lines and regions are analyzed for fixed pitch or proportional text. The lines are broken into words differently based on the kind of character spacing. Fixed pitch text is chopped immidiately by character cells. Proportional text is broken into words using definite spaces or fuzzy spaces.
-
Recognition proceeds as a two-pass process. During the first pass, attempt is made to recognize each word. The words that are satifactorily identified are passed to an adaptive classifier as training data. As a result the adaptive classifier gets a chance at improving results among text lower down on the page. In order to utilize the training of adaptive classifier on the text near the top of the page as second pass is performed, during which words that were not recognized well enough are classified again.
-
Final Phase resolves the fuzzy spaces, and checks alternative hypotheses for the x-height to locate small-cap text.
Line and Word Finding
1. Line Finding
-
Algorithm is designed so that skewed page can be recognized without having to deskew, thus preventing any loss of image quality.
-
Blob filtering and line construction are key parts of this process.
-
Under the assumption that most blobs have uniform text size, a simple percentile height filter removes drop-caps and vertically touching characters and median height approximates the text size in the region.
-
Blobs smaller than a certain fraction of the median height are filtered out, being most likely punctuation, diacritical marks and noise.
-
The filtered blobs are more likely to fit a model of non-overlapping, parallel, but sloping lines. Sorting and processing the blobs by x-coordinates makes it possible to assign blobs to a unique text line, while tracking the slope across the page.
-
Once the lines are assigned, a least median of squares fit is used to estimate the baselines, and filtered-out blobs are fitted back into appropriate lines.
-
Final step merges blobs that overlap by at least half horizontally, putting diacritical marks together with the correct base and correctly associating parts of some broken characters.
2. Baseline Fitting
- Using the text lines, baselines are fitted precisely using a quadratic spline, which allows Tesseract to handle pages with curved baselines.

- Baseline fitting is done by partitioning the blobs into groups of reasonable continuous displacement for the original straight baseline. A quadratic spline is fitted to the most populous partition by a least square fit.
3. Fixed Pitch Detection and Chopping
- Lines are tested to determine whether they are fixed pitch. Where it finds fixed pitch text, Tesseract chops the words into characters using pitch, and disables the chopper and associator on these words for the word recognition step.

4. Proportional Word Finding
- Detecting word boundaries in a not-fixed-pitch or proportional text spacing is highly non-trivial task.

-
For example, the gap between the tens and units of ‘11.9%’ is similar size to general space, but is certainly larger the kerned space between ‘erated’ and ‘junk’. Another case can be noticed that there is no horizontal gap between the bounding box of ‘of’ and ‘financial’.
-
Tesseract solves most of these problems by measuring gaps in a limited vertical range between baseline and mean line. Spaces close to a threshold are made fuzzy, where the decisions are made after word recognition.
Word Recognition
-
A major part of any word recognition algorithm is to identify how a word should be segmented into characters.
-
The initial segmented outputs from line finding is classified first. The non-fixed pitch text in the remaining text is classified using other word recognition steps.
1. Chopping Joined Characters
-
Tesseract attempts to improve the result by chopping the blob with worst confidence from the character classifier.
-
Chop points are found from concave vertices of a poligonal approximation of the outline, which may have a concave vertex opposite or a line segment. It may take upto 3 pairs of chop points to successfully separate joined characters from ASCII set.
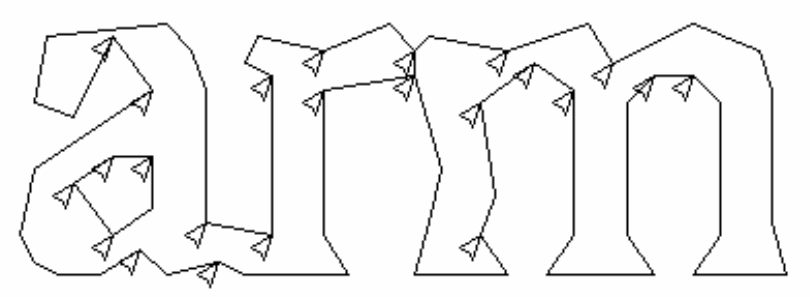
- Chops are executed in priority order. Any chop that fails to improve the confidence of the result is undone, but not completely discarded so that it can be re-used by the associator if needed.
2. Associating Broken Characters
-
After the potential chops have been exhausted, if the word is still not good enough, it is given to the associator, which makes a best first search of the segmentation graph of the possible combinations of the maximally chopped blobs into candidate characters.
-
The search pulls candidate new states from a priority queue and evaluates them by classifying unclassified combinations of fragments.
-
The chop-then-associate method is inefficient but it gives a benefit of simpler data structures that would be required to maintain the full segmentation graph.
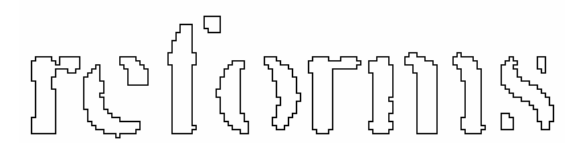
- This ability of Tesseract to successfully classify broken characters gave it an edge over the contemporaries.
Static Character Classifier
1. Features
-
Early version of Tesseract used topological features, which are independent of font and size but are not robust to issues found in real-life images.
-
Another idea for classification involved use of segments of the polygonal approximation as features, but this method is also not robust to damaged characters.
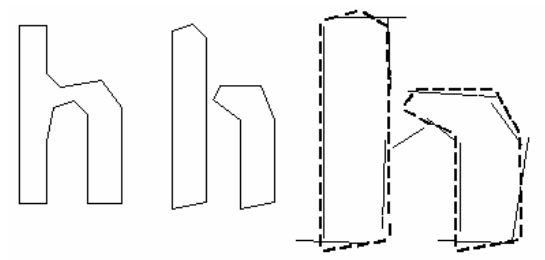
-
Solution to these problems lie in the fact that the features in the unknown need not be the same as the features in the training data. During training, segments of a polygonal approximation are used for features, but during recognition, features of a small, fixed length are extracted from the outline and matched many-to-one against the clustered prototype features of the training data.
-
The process of small features matching large prototypes is easily able to cope with recognition of damaged words. It’s main problem is that the computational cost of computing the distance between an unknown and a prototype is very high.
2. Classfication
-
This stage proceeds as a two-step process. First step involves a class pruner that creates a shortlist of character classes that the unknown might match.
-
The classes shortlisted in step one are taken further to the next step, where the actual similarity is calculated from the feature bit vectors. Each prototype character class is represented by a logical sum-of-product expression with each term called a configuration.
3. Training Data
The classifier is trained on a mere 20 samples of 94 characters from 8 fonts in a single size, but with 4 attributes (normal, bold, italic, bold italic), making the total of 60160 training samples.
Linguistic Analysis
-
Whenver the word recognition module is considering a new segmentation, the linguistic model (called permuter) choses the best available word string in the categories: Top frequent word, Top dictionary word, Top numeric word, Top UPPER case word, Top lower case word (with optional initial upper), where the final decision for segmentation is simply the word with the lowest total distance rating.
-
Since words from different segmentations may have different number of characters in them, it would be hard to compare these words directly (even if a classifier claims to produce probabilities, which Tesseract does not).
-
Tesseract instead produces two numbers to solve this issue, namely,
- Confidence, is minus the normalized distance from the prototype. It is confidence in the sense that greater the number better a metric it is.
- Rating is product of normalized distance from the prototype and total outline length in the unknown character.
Adaptive Classifier
-
OCR engines are benefitted from use of an adaptive classifier because the static classifier has to be good at generalizing to any kind of font, its ability to discriminate between different characters or between characters and non-characters is weakened.
-
Tesseract has a font-sensitive adaptive classifier that is trained using the output of the static classifiers which is commonly used to obtain greater discrimination within each document, where the number of fonts is limited.
-
It uses the same features and classifier as the static classifier to train the adaptive classifier. The only significant difference between the two classifiers apart from the training data is that the adaptive classifier uses the isotropic baseline/x-height normalization, whereas the static classifier normalizes the characters by the centroid (first moment) for position, and second moments for anisotropic size normalization.
-
The baseline normalization helps distinguish the upper and lower case characters and also improves immunity to noise specks.
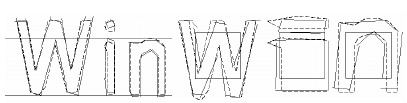
- The main benefit of character moment normalization is removal of font aspect ratio and some degree of font stroke width. It also makes recognition of subscripts and superscripts easier, but requires an additional feature to distinguish the uppercase and lowercase characters.